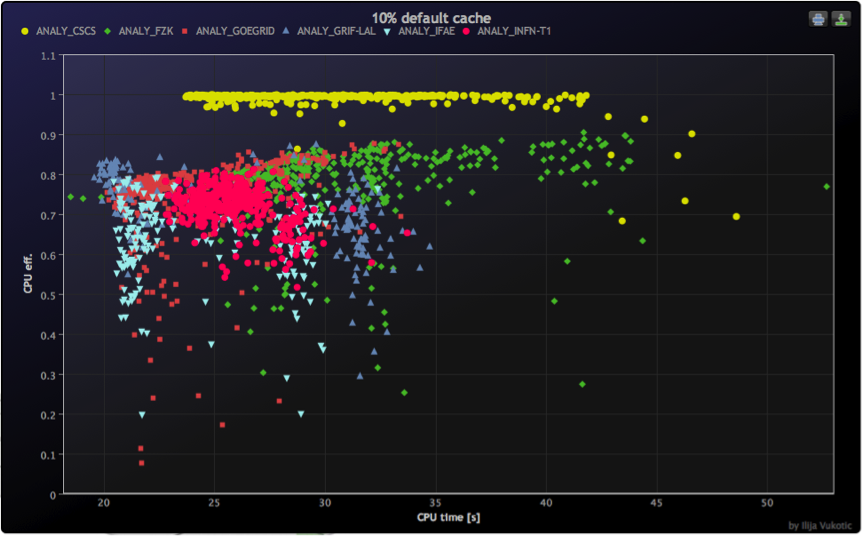
Efficiency of clusters used by CSCS to analyze CERN data up to 20% higher than comparable ones
On Feb. 16 2012, the ATLAS I/O performance tests ran a CSCS showed that the current configuration of Phoenix, the cluster providing service to the Swiss Institute of Particle Physics, outperforms in terms of efficiency all other WLCG Tier-2 sites in the world.
These tests, called HammerCloud, are periodically executed on the sites and the ATLAS organization uses them to determine which sites are more efficient.
In the following two charts we can see the CPU efficiency of CSCS (in yellow in the upper one) reaching the whopping value of 0.99, which virtually means that during these executions there was practically no I/O wait and all the CPU was available for the physicists jobs. This is about 20% more than any other measured site.


This is, in part, due to the new approach taken at CSCS in configuring the way jobs access the filesystem. Traditionally, WLCG sites did not have more than 8 concurrent jobs per compute node and, in these conditions, using a set of local disks for the scratch area is sufficient. But with the increase in the number of cores available in modern servers, the number of concurrent jobs per compute node increased linearly and, in this new environment, local disks were no longer an option: they became the true bottleneck of the system.
The solution to this problem is to use parallel file systems such as formerly Sun’s Lustre or IBM’s GPFS, which allow a relatively large set of disks, distributed across several machines, to be accessed by user jobs as if it was local disk. This way the I/O load is distributed across several storage servers, delivering an extraordinary performance while being fault tolerant.
Of course, moving the I/O load to a faster location means that the intercommunication network needs to be as quick as possible, in order to avoid incurring in delays due to network congestion. While being enough for most daily situations, 1Gb/s Ethernet cannot cope up with the new challenges and, therefore, faster network technologies such as Mellanox’s Infiniband need to be used.
The technical details
After testing GPFS in 1/3 of the cluster for nearly half a year, during the fall of 2011, CSCS engineers decided to move Phoenix’s scratch file system from Lustre to GPFS. The new configuration was ready before Dec. 2011 and was deployed on the same hardware Lustre was, but with two changes: metadata was moved from 12 SAS 15K RPM disks to 2 Virident SSDs and the RAID on the data servers was disabled, leaving it to GPFS to securely distribute the files across the system and react upon disk failure.
The network was not changed in this upgrade: the 40 Gb/s QDR Infiniband network existent proved itself to be sufficient for the tasks given.
The whole scratch system consists on 8 data servers with around 400 SATA disks in total and 2 metadata servers with one 300 GB Virident SSDs each. It outperforms by far the previous configuration, reaching a speed of 7.2 GB/sec sustained during transfers. Also, it is worth mentioning that pure metadata operations no longer affect the system, since SSD cards are much faster than any spinning disks we could add to the system.
Mentions and thanks
We would like to thank Dr. Ilija Vukotic, from the Laboratoire de l’Acclerateur Lineaire in Orsay, France, for testing Phoenix and sharing with the community the results of his benchmarks. We also congratulate the system administrators of the Phoenix cluster at CSCS for their great work (in alphabetic order): Pablo Fernandez, Miguel Gila and Jason Temple.